German Tank Problem
November 27, 2025
Introduction #
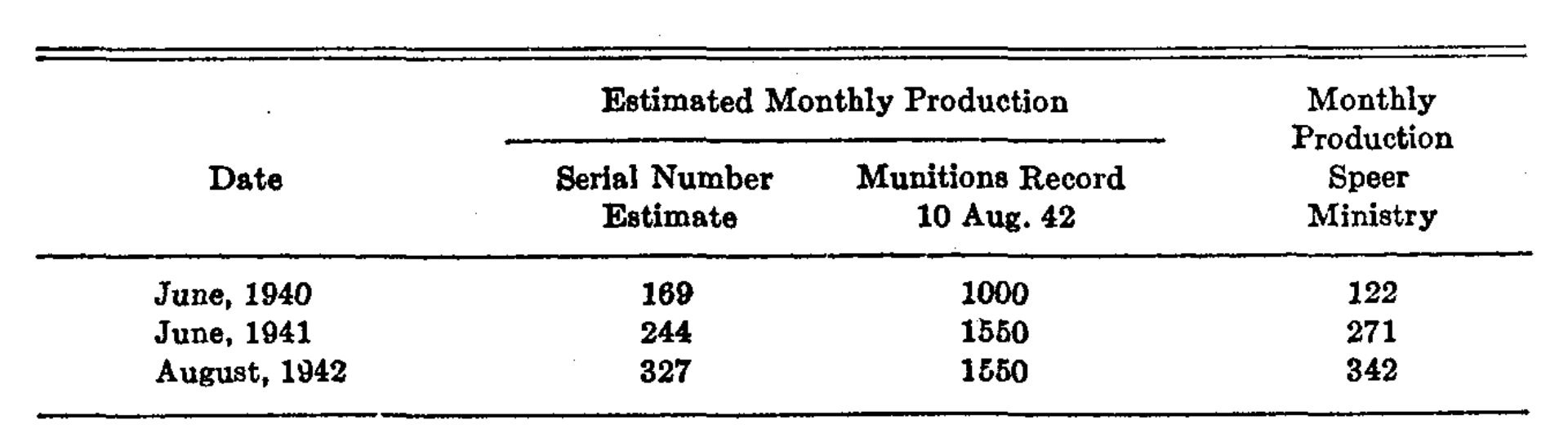
In this article, we review the famous German Tank Problem which refers to the estimation of the number of German tanks in production on a monthly basis by the Allied forces based on observations of the serial numbers of tanks, either through capture or espionage. The original report discussing the details of this problem was performed by Ruggles and Brodie, see [1] , and Figure 1 for an extract of a table (pg. 89) from the report depicting estimates for tank production both via statistical and intelligence means. Additionally, a proof of the estimators suggested to in the Ruggles and Brodie report was performed by Goodman, see [2] .
Problem Statement #
In mathematical terms, assume that we have an unknown number $N$ of German tanks being produced on a monthly basis, and that each tank is identified by a unique serial number. Assume further that the serial numbers can be mapped to the natural numbers (starting at one) whilst preserving order, where the order can be interpreted by the order in which they are produced. Assume further that we have observed $k$ tanks and our aim now is to determine an estimator, $\hat{N}$, for $N$ which is unknown.
Estimation #
Let $X_{1}, \ldots, X_{k}$ denote the random variables corresponding to the serial markings observed on German tanks. We assume that each $X_{i}$ is sampled uniformly from $\lbrace 1, \ldots, N \rbrace$ without replacement. In particular, we have that for any $i \in \lbrace 1, \ldots, k \rbrace$
$$ \begin{eqnarray} \mathbb{P} (X_{i}) & = & \frac{1}{N} . \nonumber \end{eqnarray} $$Something to note is that, while the observations are identically distributed, they are not independent since we assume no replacement (i.e. serial numbers are not reused).
For the purpose of calculations below, as the order of the statistics is not relevant (we do not care in which order the serial numbers were obtained), we consider the order statistics $X_{(1)} < \cdots < X_{(k)}$, which have a joint density
$$ \begin{eqnarray} \mathbb{P} (X_{(1)} = x_{1}, \ldots, X_{(k)} = x_{k}) & = & \left\lbrace\begin{array}{ll} \frac{1}{\binom{N}{k}} & \text{if all } x_{i} \text{ are distinct and lie within } \lbrace 1, \ldots, N \rbrace,\\ 0 & \text{otherwise} . \end{array}\right. \nonumber \end{eqnarray} $$Now, there are numerous estimators that one could use for $N$, but one must be wary of if they are biased and be conscious of their variance.
Maximum Observed Value #
If the tank number is $50$, then we know that $N \geqslant 50$, therefore a naïve first estimate could be the maximum observed value.
Let $M := \max \lbrace X_{1}, \ldots, X_{k} \rbrace = X_{(k)}$ denote the random variable corresponding to the maximum observed value, and $\hat{N}_{\text{max}} = M$ the estimator for $N$.
We now wish to determine whether $\hat{N}_{\max}$ estimator is biased and what its variance could be, for which we need the density of $M$. Whilst it is true that $X_{k}$ is uniformly distributed, $X_{(k)}$ is the ordered statistic, and is heavily biased towards larger values, and therefore is not uniformly distributed - therefore, we need to derive the density of $M$.
Let $m \in \lbrace 1, \ldots, N \rbrace$, then the total number of possible outcomes of our samplings is $\binom{N}{k}$, and out of these, the total number of outcomes where the maximum is $m$ is the number of ways of choosing $k - 1$ numbers below $m$, i.e. $\binom{m - 1}{k - 1}$. Therefore
$$ \begin{eqnarray} \mathbb{P} (M = m) & = & \left\lbrace\begin{array}{ll} \frac{\binom{m - 1}{k - 1}}{\binom{N}{k}} & \text{if } k \leqslant m \leqslant N,\\ 0 & \text{otherwise} . \end{array}\right. . \nonumber \end{eqnarray} $$Hence
$$ \begin{eqnarray} \mathbb{E} (M) & = & \sum_{m = 1}^N m\mathbb{P} (M = m), \nonumber\\\ \text{after much simplification } \rightsquigarrow & = & \frac{k}{k + 1} (N + 1), \nonumber \end{eqnarray} $$and
$$ \begin{eqnarray} \mathbb{V} (M) & = & \frac{k (N + 1) (N - k)}{(k + 1)^2 (k + 2)} . \nonumber \end{eqnarray} $$In particular, we see that
$$ \begin{eqnarray} \mathbb{E} \left( \hat{N}_{\text{max}} \right) & = & \frac{k}{k + 1} (N + 1), \nonumber\\\ & = & N - \left( \frac{N - k}{k + 1} \right) < N, \nonumber\\\ \mathbb{V} (\hat{N}_{\max}) & = & \frac{k (N + 1) (N - k)}{(k + 1)^2 (k + 2)}, \nonumber \end{eqnarray} $$i.e. that the estimator is biased, and will systematically underestimate $N$, with the underestimation gap becoming more severe with increasing $N$.
Method of Moments #
We know that each $X_{i}$ is uniformly distributed across $\lbrace 1, \ldots, N \rbrace$, and with that, for all $i \in \lbrace 1, \ldots, k \rbrace$
$$ \begin{eqnarray} \mu := \mathbb{E} (X_{i}) & = & \frac{N + 1}{2}, \nonumber \end{eqnarray} $$giving us the identity $N = 2 \mu - 1$. If we are able to obtain an estimator for $\mu$, we can also do so for $N$. Letting $\bar{X} := \frac{1}{k} (X_{1} + \cdots + X_{k})$ denote the sample mean, $\bar{X}$ provides an unbiased estimator of $\mu$, i.e.
$$ \begin{eqnarray} \mathbb{E} (\bar{X}) & = & \mu \nonumber \end{eqnarray} $$and indeed, with that, we are able to obtain the estimator $\hat{N}_{\text{MoM}} := 2 \bar{X} - 1$, for which we have
$$ \begin{eqnarray} \mathbb{E} \left( \hat{N}_{\text{MoM}} \right) & = & N, \nonumber\\\ \mathbb{V} \left( \hat{N}_{\text{MoM}} \right) & = & \frac{(N + 1) (N - k)}{3 k} . \nonumber \end{eqnarray} $$Maximum Likelihood #
Denote by $\boldsymbol{x} = (x_{1}, \ldots, x_{k})$ an observed sample of serial numbers, and $\boldsymbol{X}= (X_{1}, \ldots, X_{k})$. Then for $N \in \lbrace k, k + 1, \ldots \rbrace$, the likelihood function (representing the probability of observing this specific sample given a population size $N$) is defined as
$$ \begin{eqnarray} L (N| \boldsymbol{x}) & := & \mathbb{P} (X_{(1)} = x_{1}, \ldots, X_{(k)} = x_{k} |N), \nonumber\\\ & = & \left\lbrace\begin{array}{ll} \frac{1}{\binom{N}{k}} & \text{if } N \geqslant \max \lbrace x_{1}, \ldots, x_{k} \rbrace,\\ 0 & \text{otherwise} . \end{array}\right. \nonumber \end{eqnarray} $$For brevity, in the following we write $L (N)$ to denote $L (N| \boldsymbol{x})$. Now, we want to determine the maximum likelihood - the likelihood is strictly decreasing (since its reciprocal is strictly increasing) in $N$,
$$ \begin{eqnarray} \frac{L (N + 1)}{L (N)} & = & 1 - \frac{k}{N + 1} < 1 \nonumber \end{eqnarray} $$i.e. $L (N + 1) < L (N)$ for any $N \geqslant \max \lbrace x_{1}, \ldots, x_{k} \rbrace$. Therefore, the $N$ which maximises the likelihood is $\max \lbrace x_{1}, \ldots, x_{k} \rbrace$, giving the estimator
$$ \begin{eqnarray} \hat{N}_{\text{MLE}} & = & \max \lbrace X_{1}, \ldots, X_{k} \rbrace, \nonumber \end{eqnarray} $$which we have covered above.
“Best” Estimators #
A question one can ask themselves is, what is the best estimator to $N$? Well, this entirely depends on what is mean’t by best. One common technique that is used in literature is finding estimators that minimise the mean squared error (MSE), although other loss functions can also be used, see Chapter 7.3.4 of [3] for a discussion on the use of alternative loss functions.
Definition.
The mean squared error of an estimator $W$ of a parameter $\theta$ is
$$ \begin{eqnarray} \text{MSE} (\theta) & := & \mathbb{E}_{\theta} [(W - \theta)^2] \nonumber\\\ & = & \mathbb{V}_{\theta} (W) + \text{Bias}_{\theta} (W)^2 \nonumber \end{eqnarray} $$where $\text{Bias}_{\theta} (W) := \mathbb{E}_{\theta} (W) - \theta$.
Having defined the MSE, we can now search for an estimator that has the best MSE across all parameters $\theta$. But this is not always possible, in fact, one can often find two estimators that outperform each other with respect to the MSE across different parameter ranges. The reason for this difficulty is that the space of all estimators is quite large.
UMVUE #
To obtain a recommended estimator, many resort to restricting to the space of unbiased estimators, i.e. those such that $\mathbb{E}_{\theta} (W) = \theta$. In such a scenario, the MSE simply corresponds to the variance of the estimators, and therefore the estimators we seek are those that have uniformly smallest variance.
Should I always use an unbiased estimator? No. In many cases, one can make a large improvement on the variance by forgiving some unbiasedness, and with that achieve a much better MSE. Although unbiased estimators as ideal, they are not always the best!
Definition (UMVUE).
An estimator $W^{\ast}$ is the uniform minimum variance unbiased estimator (UMVUE) of $\theta$ if it satisfies $\mathbb{E}_{\theta} (W^{\ast}) = \theta$ for all $\theta$, and for any other estimator $W$ with $\mathbb{E}_{\theta} (W) = \theta$, we have $\mathbb{V}_{\theta} (W^{\ast}) \leqslant \mathbb{V}_{\theta} (W)$ for all $\theta$.
Finding the UMVUE is not an easy task, it may not exist, and even if it does, it is difficult to know from first principles how to obtain one. It could be possible that from the estimators already obtained for a given problem, that at one of them is the UMVUE, but how can one know unless the inequality can be proven across all possible estimators.
Cramér-Rao Inequality - A Short Detour #
One way to get around the issue of knowing when to stop is to know first what is the lowest possible variance one could possible strive to obtain, and then check if your estimator attains this bound – this is where the Cramér-Rao inequality comes in.
Theorem (Cramér-Rao Inequality).
Let $X_{1}, \ldots, X_{n}$ be a sample with pdf $f (\boldsymbol{x} | \theta)$, sample space $\mathcal{X}$, and parameter $\theta$, and let $W (\boldsymbol{X}) = W (X_{1}, \ldots, X_{n})$ be any estimator satisfying
$$ \begin{eqnarray} \frac{\mathrm{d}}{\mathrm{d} \theta} \mathbb{E}_{\theta} (W (\boldsymbol{X})) & = & \int_{\mathcal{X}} \frac{\partial}{\partial \theta} [W (\boldsymbol{x}) f (\boldsymbol{x} | \theta)] \mathrm{d} \boldsymbol{x}, \nonumber\\\ \mathbb{V}_{\theta} (W (\boldsymbol{X})) & < & \infty, \nonumber \end{eqnarray} $$or equivalent for discrete random variables. Then
$$ \begin{eqnarray} \mathbb{V}_{\theta} (W (\boldsymbol{X})) & \geqslant & \frac{\left( \frac{\mathrm{d}}{\mathrm{d} \theta} \mathbb{E}_{\theta} (W (\boldsymbol{X})) \right)^2}{\mathbb{I}_{\theta} (\boldsymbol{X})}, \nonumber \end{eqnarray} $$where $\mathbb{I}_{\theta}$ is called the information number, or Fischer information of the sample, and is defined as
$$ \begin{eqnarray} \mathbb{I}_{\theta} (\boldsymbol{X}) & := & \mathbb{E}_{\theta} \left( \left( \frac{\partial}{\partial \theta} \log f (\boldsymbol{X}| \theta) \right)^2 \right) \nonumber\\\ & = & \mathbb{E}_{\theta} \left( - \frac{\partial^2}{\partial \theta^2} \log f (\boldsymbol{X}| \theta) \right) \nonumber \end{eqnarray} $$Corollary (Cramér-Rao Inequality - Unbiased Case).
Let $X_{1}, \ldots, X_{n}$ be a sample with pdf $f (\boldsymbol{x} | \theta)$ and let $W (\boldsymbol{X}) = W (X_{1}, \ldots, X_{n})$ be an unbiased estimator with $\mathbb{V}_{\theta} (W (\boldsymbol{X})) < \infty$. Then
$$ \begin{eqnarray} \mathbb{V}_{\theta} (W (\boldsymbol{X})) & \geqslant & \frac{1}{\mathbb{I}_{\theta} (\boldsymbol{X})} . \nonumber \end{eqnarray} $$The Cramér-Rao inequality is quite remarkable and also quite intuitive - it tells us that as more information is made available (i.e. as $\mathbb{I}_{\theta}$ increases), we can, in theory, obtain estimators that have smaller and smaller variances. Although, the attainment is not guaranteed.
If we have found an estimators that attains this bound, then we know (assuming that the conditions are met) that our estimator is optimal with respect to the variance, and is a UMVUE if it is also unbiased. Thankfully, the requirements for attainment of the Cramér-Rao bound are simple, although again, these requirements do not provide a means of constructing the optimal estimator.
Corollary (Attainment).
Let $X_{1}, \ldots, X_{n}$ be a sample with pdf $f (\boldsymbol{x} | \theta)$ and let $W (\boldsymbol{X}) = W (X_{1}, \ldots, X_{n})$ be any estimator satisfying the Cramér-Rao conditions. Then $W (\boldsymbol{X})$ attains the Cramér-Rao lower bound if and only if there exists a function $a (\theta)$ such that
$$ \begin{eqnarray} a (\theta) [W (\boldsymbol{x}) - \theta] & = & \frac{\partial}{\partial \theta} \log f (\boldsymbol{x} | \theta) \qquad \text{for all } \theta . \nonumber \end{eqnarray} $$We should note that the key assumption of the Cramér-Rao theorem is the requirement that we can differentiate under the integral sign, a condition that needs to be checked and is not always true.
Can we obtain a Cramér-Rao bound for our German tank problem? Unfortunately, no. For the German tank problem, we have
$$ \begin{eqnarray} f (x_{1}, \ldots, x_{k} |N) & = & \frac{1}{\binom{N}{k}} \boldsymbol{1}_{\lbrace \max \lbrace x_{1}, \ldots, x_{k} \rbrace \leqslant N \rbrace}, \nonumber \end{eqnarray} $$in particular, the support of our density depends on our parameter $N$. Due to this, we cannot simply differentiate under the integral without taking into consideration the boundary terms of the support. Let $S_{N} := \lbrace \boldsymbol{x} = \lbrace x_{1}, \ldots, x_{k} \rbrace | \max (\boldsymbol{x}) \leqslant N \rbrace$ denote the support of $f$, then, by the Leibniz rule for differentiating an integral (apply counting measure and proceed usually), for any estimator $W$ of $N$
$$ \begin{eqnarray} \frac{\mathrm{d}}{\mathrm{d} N} \mathbb{E} (W (\boldsymbol{x})) & = & \sum_{\boldsymbol{x} \in S_{N}} W (\boldsymbol{x}) \frac{\mathrm{d}}{\mathrm{d} N} f (\boldsymbol{x} |N) + \text{Boundary Terms} \nonumber \end{eqnarray} $$where the Boundary Terms come from the dependence of the support on the parameter $N$, and are non-zero. As such, the Cramér-Rao bounds do not apply.
Constructing the UMVUE #
Thankfully, there exists some developed theory for constructing better unbiased estimators (those with lower variance), and also the UMVUE. Before we state these results, we need to understand what is a sufficient statistic.
A sufficient statistic for a parameter $\theta$ is a statistic that, in a certain sense, captures all the information about $\theta$ contained in the sample, i.e. if $T (\boldsymbol{X})$ is a sufficient statistic for $\theta$, then any inference about $\theta$ should depend on the sample $\boldsymbol{X}$ only through the value of $T (\boldsymbol{X})$.
Definition (Sufficient Statistic).
A statistic $T (\boldsymbol{X})$ is a sufficient statistic for $\theta$ if the conditional distribution of the sample $\boldsymbol{X}$ given the value of $T (\boldsymbol{X})$ does not depend on $\theta$.
How can we know if we have a sufficient statistic? For this, there is a simple result called the Factorisation Theorem, see [3] (Theorem 6.2.6), that allows to us to quickly identify such statistics.
Theorem (Factorisation Theorem).
Let $f (\boldsymbol{x} | \theta)$ denote the joint pdf of a sample $\boldsymbol{X}$. A statistic $T (\boldsymbol{X})$ is a sufficient statistic for $\theta$ if and only if there exists functions $g (t| \theta)$ and $h (\boldsymbol{x})$ such that, for all sample points $\boldsymbol{x}$ and all parameters $\theta$
$$ f (\boldsymbol{x} | \theta) = g (T (\boldsymbol{x}) | \theta) h (\boldsymbol{x}) . $$Through the concept of sufficiency, we arrive at the remarkable result by Rao-Blackwell, see [3] (Theorem 7.3.17), which allows us to improve upon any unbiased estimator if one has access to any sufficient statistic for $\theta$, no matter how crude. This process of applying the Rao-Blackwell theorem is called Rao-Blackwellisation.
Theorem (Rao-Blackwell).
Let $W$ be any unbiased estimator of $\theta$, and $T$ be a sufficient statistic for $\theta$. Define by $\phi (T) := \mathbb{E} (W|T)$. Then $\mathbb{E}_{\theta} (\phi (T)) = \theta$ and $\mathbb{V}_{\theta} (\phi (T)) \leqslant \mathbb{V}_{\theta} (W)$ for all $\theta$, that is $\phi (T)$ is a uniformly better unbiased estimator of $\theta$ (note, $\phi$ is not necessarily the UMVUE).
How about if I wanted to construct the UMVUE, and not just improve upon my estimator? For that, we rely on the concept of completeness and the Lehmann-Scheffé theorem, see [3] (Theorem 7.3.19, Theorem 7.3.23, Theorem 7.5.1) which also tells us that any UMVUE is unique!
Definition (Completeness).
Let $f (t| \theta)$ be a family of densities for a statistic $T (\boldsymbol{X})$. The family of probability distributions is called complete if $\mathbb{E}_{\theta} (g (T)) = 0$ for all $\theta$ implies $\mathbb{P}_{\theta} (g (T) = 0) = 1$ for all $\theta$. Equivalently, $T (\boldsymbol{X})$ is called a complete statistic.
Theorem (Lehmann-Scheffé).
Let $T$ be a complete sufficient statistic for a parameter $\theta$, and let $\phi (T)$ be any estimator based only on $T$ such that $\mathbb{E} (\phi (T)) = \theta$. Then $\phi (T)$ is the unique UMVUE of $\theta$.
That is, if we are able to find a complete sufficient statistic of our parameter $\theta$, then by conditioning any estimator on this statistic will necessarily yield the UMVUE.
Back to the German Tank Problem #
Having determined how to obtain the UMVUE, we now move to construct it for the German tank problem. Recall the estimators that we determined for $N$, in particular $\hat{N}_{\operatorname{MoM}}$ and $\hat{N}_{\max}$,
$$ \begin{eqnarray} \hat{N}_{\operatorname{MoM}} & = & 2 \bar{X} - 1, \nonumber\\\ \mathbb{E} (\hat{N}_{\operatorname{MoM}}) & = & N, \nonumber\\\ \mathbb{V} (\hat{N}_{\operatorname{MoM}}) & = & \frac{(N + 1) (N - k)}{3 k} . \nonumber \end{eqnarray} $$and
$$ \begin{eqnarray} \hat{N}_{\max} & = & \max \lbrace x_{1}, \ldots, x_{k} \rbrace, \nonumber\\\ \mathbb{E} (\hat{N}_{\max}) & = & N - \left( \frac{N - k}{k + 1} \right), \nonumber\\\ \mathbb{V} (\hat{N}_{\max}) & = & \frac{k (N + 1) (N - k)}{(k + 1)^2 (k + 2)} . \nonumber \end{eqnarray} $$The first question we ask is, can we improve either of these via conditioning, i.e. via Rao-Blackwellisation? We can if at least one of our estimators is sufficient.
We start with checking $\hat{N}_{\operatorname{MoM}}$. Recalling the Factorisation Theorem, to show that an estimator is sufficient, it suffices to determine if we can factorise the density $f (\boldsymbol{x} |N)$ into
$$ \begin{eqnarray} f (\boldsymbol{x} |N) & = & h (\boldsymbol{x}) g (\boldsymbol{x}, \hat{N}_{\operatorname{MoM}}) \nonumber \end{eqnarray} $$for some $h, g$. Knowing that
$$ \begin{eqnarray} f (\boldsymbol{x} |N) & = & \mathbb{P} (X_{(1)} = x_{1}, \ldots, X_{(k)} = x_{k} |N) = \frac{1}{\binom{N}{k}} \boldsymbol{1}_{\lbrace \max \lbrace x_{1}, \ldots, x_{k} \rbrace \leqslant N \rbrace} \nonumber \end{eqnarray} $$we see that it is not possible to write the indicator $\boldsymbol{1}_{\lbrace \max \lbrace x_{1}, \ldots, x_{k} \rbrace \leqslant N \rbrace}$ solely in terms of $\bar{X}$, and therefore also not solely in terms of $\hat{N}_{\operatorname{MoM}}$, therefore $\hat{N}_{\operatorname{MoM}}$ is not sufficient.
Although, looking at the density, we see that the estimator $\hat{N}_{\max}$ is sufficient, as one can write
$$ \begin{eqnarray} f (\boldsymbol{x} |N) & = & \frac{1}{\binom{N}{k}} \boldsymbol{1}_{\lbrace \hat{N}_{\max} (\boldsymbol{x}) \leqslant N \rbrace} \nonumber \end{eqnarray} $$and choosing $h \equiv 1$ and $g (\boldsymbol{x}, \hat{N}_{\max}) = \frac{1}{\binom{N}{k}} \boldsymbol{1}_{\lbrace \hat{N}_{\max} (\boldsymbol{x}) \leqslant N \rbrace}$ gives us the required factorisation.
So what does this all mean? Although $\hat{N}_{\operatorname{MoM}}$ is not a sufficient statistic, it is unbiased (unlike $\hat{N}_{\max}$), so we can condition it with the sufficient statistic $\hat{N}_{\max}$ to obtain a uniformly better unbiased estimate than $\hat{N}_{\operatorname{MoM}}$.
For brevity, let $M = \hat{N}_{\max}$ and define $\phi (m) := \mathbb{E} (\hat{N}_{\operatorname{MoM}} |M = m)$ for some $m \in \lbrace k, k + 1, \ldots \rbrace$. Then, as an estimator, $\phi$ can be written as
$$ \begin{eqnarray} \phi (M) & = & \mathbb{E} (2 \bar{X} - 1| M), \nonumber\\\ & = & \frac{2}{k} \sum_{i = 1}^k \mathbb{E} (X_{i} |M) - 1. \nonumber \end{eqnarray} $$By the law of total expectation,
$$ \begin{eqnarray} \mathbb{E} (X_{i} |M = m) & = & \mathbb{E} (X_{i} |M = m, X_{i} = m) \mathbb{P} (X_{i} = m) +\mathbb{E} (X_{i} |M = m, X_{i} \neq m) \mathbb{P} (X_{i} \neq m) \nonumber\\\ & = & m \frac{1}{k} + \frac{1 + (m - 1)}{2} \frac{k - 1}{k} \nonumber\\\ & = & \frac{m (k + 1)}{2 k}, \nonumber \end{eqnarray} $$which allows us to write the estimator $\phi (M)$ as
$$ \begin{eqnarray} \phi (M) & = & \frac{2}{k} \sum_{i = 1}^k \mathbb{E} (X_{i} |M) - 1, \nonumber\\\ & = & M \left( \frac{k + 1}{k} \right) - 1. \nonumber \end{eqnarray} $$In particular, by the Rao-Blackwell theorem, we have obtained the estimator $\hat{N}_{\operatorname{RB}} := \phi (M) = M \left( \frac{k + 1}{k} \right) - 1$ which provides a uniformly better unbiased estimator than $\hat{N}_{\operatorname{MoM}}$.
Indeed, we can see that
$$ \begin{eqnarray} \mathbb{E} (\boldsymbol{} \hat{N}_{\operatorname{RB}}) & = & \mathbb{E} (M) \left( \frac{k + 1}{k} \right) - 1, \nonumber\\\ & = & N, \nonumber\\\ \mathbb{V} (\hat{N}_{\operatorname{RB}}) & = & \left( \frac{k + 1}{k} \right)^2 \mathbb{V} (M), \nonumber\\\ & = & \frac{(N + 1) (N - k)}{k (k + 2)}, \nonumber \end{eqnarray} $$i.e. $\mathbb{V} (\hat{N}_{\operatorname{RB}}) <\mathbb{V} (\hat{N}_{\operatorname{MoM}})$ for $k > 1$.
Now, the question then is, is $\hat{N}_{\operatorname{RB}}$ the UMVUE? For this, we need to check whether the family of densities for the estimator $M = \hat{N}_{\max}$ is complete.
Let $g$ be any function of $M$ such that $\mathbb{E} (g (M)) = 0$, then it suffices to show that $\mathbb{P} (g (M) = 0) = 1$ for all $N$. Applying the definition of the expectation, we see that, under $k$ samples
$$ \begin{eqnarray} 0 =\mathbb{E} (g (M)) & = & \sum_{m = 1}^N g (m) \mathbb{P} (M = m|N), \nonumber\\\ & = & \sum_{m = k}^N g (m) \mathbb{P} (M = m|N) \nonumber\\\ \text{from above } \rightsquigarrow & = & \sum_{m = k}^N g (m) \frac{\binom{m - 1}{k - 1}}{\binom{N}{k}} . \nonumber \end{eqnarray} $$Since $\binom{N}{k} > 0$, we can multiply out to obtain
$$ \begin{eqnarray} \sum_{m = k}^N g (m) \binom{m - 1}{k - 1} & = & 0 \qquad \text{for all } N \in \lbrace k, k + 1, \ldots \rbrace . \nonumber \end{eqnarray} $$We now show that $g (m) = 0$ for $m \in \lbrace k, \ldots, N \rbrace$ via an inductive argument. As a base case, consider $N = k$. Then
$$ \begin{eqnarray} 0 = \sum_{m = k}^k g (m) \binom{m - 1}{k - 1} & = & g (k), \nonumber \end{eqnarray} $$and therefore $g (k) = 0$. Assume now that the statement holds true for an arbitrary $N$, then we wish to prove this for $N + 1$. Indeed,
$$ \begin{eqnarray} 0 = \sum_{m = k}^{N + 1} g (m) \binom{m - 1}{k - 1} & = & \sum_{m = k}^N g (m) \binom{m - 1}{k - 1} + g (N + 1) \binom{N}{k - 1} . \nonumber \end{eqnarray} $$Since the case is assumed to hold true for $N$, we have that
$$ \begin{eqnarray} \sum_{m = k}^N g (m) \binom{m - 1}{k - 1} & = & 0 \nonumber \end{eqnarray} $$and therefore
$$ \begin{eqnarray} 0 & = & g (N + 1) \binom{N}{k - 1} \nonumber \end{eqnarray} $$and hence $g (N + 1) = 0$, i.e. the case holds true also for $N + 1$, which concludes the inductive proof, i.e. $g (M) = 0$. In particular, we have
$$ \begin{eqnarray} \mathbb{E} (g (M)) = 0 & \Rightarrow & \mathbb{P} (g (M) = 0) = 1, \nonumber \end{eqnarray} $$i.e. $M$ is also a complete statistic. In particular, that $\hat{N}_{\operatorname{RB}} := \phi (\hat{N}_{\max}) = M \left( \frac{k + 1}{k} \right) - 1$ is the UMVUE.
References
- Richard Ruggles and Henry Brodie (1947). An Empirical Approach to Economic Intelligence in World War II. 42 (237) : 72–91. doi:10.1080/01621459.1947.10501915 link
- Leo A. Goodman (1952). Serial Number Analysis. 47 (260) : 622–634. doi:10.1080/01621459.1952.10483442 link
- George Casella and Roger L. Berger (2002). Statistical Inference.